Data Management
File Systems
File System |
Path |
Quota |
Snapshots |
Purged |
Key Features |
|---|---|---|---|---|---|
HOME |
|
100 GB. 750,000 files per user. |
Yes (30 days) |
No |
Area for software, scripts, job files, and so on. Not intended as a source/destination for I/O during jobs. |
PROJECTS |
|
500 GB. Up to 1-25 TB by allocation request. Large requests may have a monetary fee. |
No/TBA |
No |
Area for shared data for a project, common data sets, software, results, and so on. |
WORK - HDD |
|
1000 GB. Up to 1-100 TB by allocation request. Submit a support request. |
No |
No |
Area for computation, largest allocations, where I/O from jobs should occur. (this is now your scratch volume) |
WORK - NVME |
|
NVME space is available upon request; submit a support request. |
No |
No |
Area for computation, NVME is best for lots of small I/O from jobs. |
/tmp |
|
0.74 (CPU) or 1.50 TB (GPU) shared or dedicated depending on node usage by job(s), no quotas in place. |
No |
After each job |
Locally attached disk for fast small file I/O. |
File System Notes
Each user has a home directory, $HOME, located at
/u/$USER. For each project they are assigned to, they will also have access to shared file space under/projectsand/work/hdd.For example, a user (with username: auser) who has an allocated project with a local project serial code abcd will see the following entries in their $HOME and entries in the
/projectsand/work/hddfile systems.$ ls -ld /u/$USER drwxrwx---+ 12 root root 12345 Feb 21 11:54 /u/$USER $ ls -ld /projects/abcd drwxrws---+ 45 root delta_abcd 4096 Feb 21 11:54 /projects/abcd $ ls -l /projects/abcd total 0 drwxrws---+ 2 auser delta_abcd 6 Feb 21 11:54 auser drwxrws---+ 2 buser delta_abcd 6 Feb 21 11:54 buser ... $ ls -ld /work/hdd/abcd drwxrws---+ 45 root delta_abcd 4096 Feb 21 11:54 /work/hdd/abcd $ ls -l /work/hdd/abcd total 0 drwxrws---+ 2 auser delta_abcd 6 Feb 21 11:54 auser drwxrws---+ 2 buser delta_abcd 6 Feb 21 11:54 buser ...
Determine the mapping of ACCESS project to local project using the
accountscommand. View your file system usage with thequotacommand.Directory access changes can be made using the facl command. Submit a support request if you need assistance enabling access for specific users and projects.
A “module reset” in a job script populates $WORK and $SCRATCH environment variables automatically, or you may set them as
WORK=/projects/<account>/$USER,SCRATCH=/scratch/<account>/$USER.
/tmp on Compute Nodes (Job Duration)
The high performance ssd storage (740GB CPU, 1.5TB GPU) is available in /tmp (unique to each node and job – not a shared file system) and may contain less than the expected free space if the node(s) are running multiple jobs.
Codes that need to perform i/o to many small files should target /tmp on each node of the job and save results to other file systems before the job ends.
File System Snapshots
Daily snapshots are run on the file system for the /u area.
These snapshots allow you to go back to a point in time and retrieve data you may have accidentally modified, deleted, or overwritten.
These snapshots are not backups and reside on the same hardware as the primary copy of the data.
To access snapshots for data in your /u directory, run cd ~/.snapshot/snapshot-daily-_YYYY-MM-DD_HH_mm_ss_UTC/ where “YYY-MM-DD_HH_mm_ss” is the timestamp of the snapshot you want to recover from.
To list the available snapshots, run the command: ls ~/.snapshot/
Quota Usage
The quota command allows you to view your use of the file systems and use by your projects.
Below is a sample output for a person, “<user>”, who is in two projects: “aaaa” and “bbbb”.
The home directory quota does not depend on which project group the file is written with.
[<user>@dt-login01 ~]$ quota
Quota usage for user <user>:
-------------------------------------------------------------------------------------------
| Directory Path | User | User | User | User | User | User |
| | Block| Soft | Hard | File | Soft | Hard |
| | Used | Quota| Limit | Used | Quota | Limit|
--------------------------------------------------------------------------------------
| /u/<user> | 20k | 50G | 27.5G | 5 | 600000 | 660000 |
--------------------------------------------------------------------------------------
Quota usage for groups user <user> is a member of:
-------------------------------------------------------------------------------------
| Directory Path | Group | Group | Group | Group | Group | Group |
| | Block | Soft | Hard | File | Soft | Hard |
| | Used | Quota | Limit | Used | Quota | Limit |
-------------------------------------------------------------------------------------------
| /projects/aaaa | 8k | 500G | 550G | 2 | 300000 | 330000 |
| /projects/bbbb | 24k | 500G | 550G | 6 | 300000 | 330000 |
| /work/hdd/aaaa | 8k | 552G | 607.2G| 2 | 500000 | 550000 |
| /work/hdd/bbbb | 24k | 9.766T| 10.74T| 6 | 500000 | 550000 |
------------------------------------------------------------------------------------------
Access to Data
Current ACCESS policy is for user access to be removed if a user is not a member of any active project on Delta. Delta does not provide storage resources for archiving data or other long-term storage. There is a 30-day grace period for expired Delta projects to allow for data management access only.
File Sharing
Users may share files from the /projects file system on Delta to external users via Globus.
Create a directory to share from in your /projects directory. If your four-character allocation code is “XXXX” then do something like:
mkdir /projects/XXXX/globus_shared/
mkdir /projects/XXXX/globus_shared/my_data/
Then move or copy whatever data you want to share to that directory.
Follow the instructions on this Globus sharing page to share that directory. You will need to authenticate and connect to the “ACCESS Delta” endpoint to make this work. Share the collection from the directory you created; in the above example: “/projects/XXXX/globus_shared/my_data/”.
Transferring Data
Note
ssh/scp/sftp will work with Duo MFA. A good first step is to use the interactive (not stored/saved) password option with these apps. The interactive login should present you with the first password prompt (your Kerberos password) followed by the second password prompt for Duo (push to device or passcode from the Duo app).Secure Copy (scp)
Use scp for small to modest transfers to avoid impacting the usability of the Delta login node. Go to Transferring Files - scp for instructions on using scp on NCSA computing resources.
rsync
Use rsync for small to modest transfers to avoid impacting the usability of the Delta login node. Go to Transferring Files - rsync for instructions on using rsync on NCSA computing resources.
Globus
Use Globus for large data transfers. Globus is a web-based file transfer system that works in the background to move files between systems with Globus endpoints.
Go to Transferring Files - Globus for instructions on using Globus with NCSA computing resources.
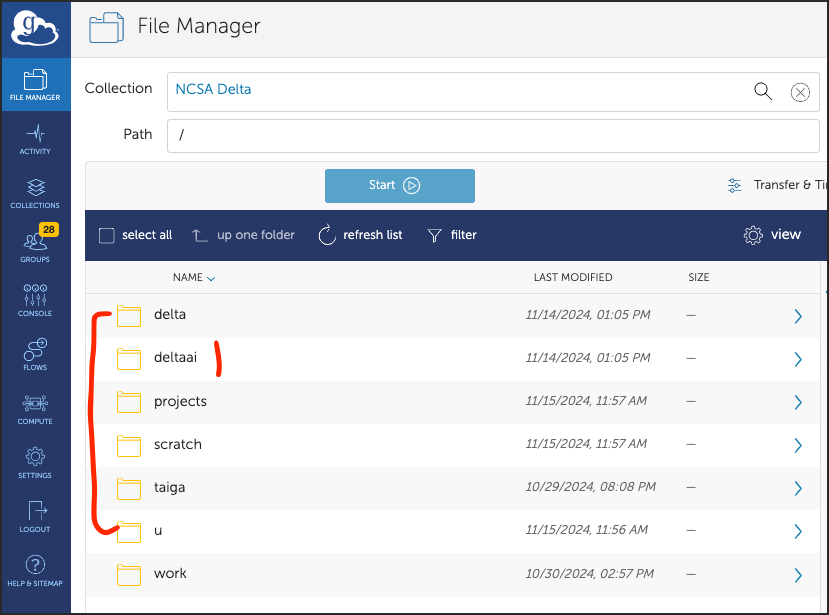
The Delta and DeltaAI endpoints are the same. Delta and DeltaAI can see /work/hdd and /work/nvme, and the Delta and DeltaAI home directories will be visible. The Delta endpoint collection names are:
“NCSA Delta” (authenticates with your NCSA identity)
“ACCESS Delta” (authenticates with your ACCESS identity)
The endpoint landing location (/) in Globus shows both home directories, and folders for shared project and work file systems.
The u and delta folders navigate to
/u/${USER}on Delta.The deltaai folder navigates to
/u/${USER}on DeltaAI.Note that Delta and DeltaAI have different home directories; the CPUs are different, incompatible architectures.