System Architecture
DeltaAI is designed to support applications needing GPU computing power and access to larger memory. DeltaAI has some important architectural features to facilitate new discovery and insight:
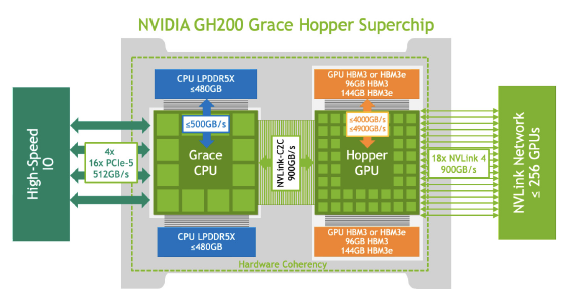
A single CPU architecture (ARM) and GPU architecture in the NVIDIA GH200 (Grace Hopper superchip).
A low latency and high bandwidth HPE/Cray Slingshot interconnect between compute nodes.
Lustre for home, projects, and scratch file systems.
Support for relaxed and non-POSIX I/O (feature not yet implemented)
Shared-node jobs with the smallest allocatable unit being 1 GH200 superchip.
Resources for persistent services in support of Gateways, Open OnDemand, and Data Transport nodes
DeltaAI GH200 Compute Nodes
The Delta compute ecosystem is composed of a single node type:
A quad or 4-way Grace-Hopper node based on the GH200 superchip.
Each superchip has a connected Slingshot11 Cassini NIC totaling 4 NICs per node.
Each Grace-Hopper GH200 superchip has a Grace ARM 72-core CPU with 120 GB of memory and a NVIDIA H100 GPU with 96GB of memory.
4-Way NVIDIA GH200 GPU Compute Node Specifications
Specification |
Value |
|---|---|
Number of nodes |
152* |
GPU |
NVIDIA H100 |
GPUs per node |
4 (1 per superchip) |
GPU Memory (GB) |
96 |
CPU |
NVIDIA Grace |
CPU sockets per node |
4 |
Cores per socket |
72 (1 superchip) |
Cores per node |
288 |
Hardware threads per core |
1 (SMT off) |
Hardware threads per node |
288 |
Clock rate (GHz) |
~ 3.35 |
CPU RAM (GB) GPU (Gb) |
480GB (120GB per CPU) LPDDR5 384GB (96 GB per GPU) HBM3 |
Cache (MiB) L1/L2/L3 |
18 / 288 / 456 |
Local storage (TB) |
3.9 TB |
NIC (4 per node) |
4x200GbE |
The Grace ARM CPUs have 1 NUMA domain per superchip.
* All nodes are in a single partition and any job can span any node. Node funding sources are: 132 nodes - NSF/NAIRR; 20 nodes - Illinois Computes.
References
4-Way NVIDIA GH200 Mapping and GPU-CPU Affinitization
GPU0 |
GPU1 |
GPU2 |
GPU3 |
HSN |
CPU Affinity |
NUMA Affinity |
GPU NUMA ID |
|
|---|---|---|---|---|---|---|---|---|
GPU0 |
X |
NV6 |
NV6 |
NV6 |
hsn0 |
0-71 |
0 |
4 |
GPU1 |
NV6 |
X |
NV6 |
NV6 |
hsn1 |
72-143 |
1 |
12 |
GPU2 |
NV6 |
NV6 |
X |
NV6 |
hsn2 |
144-215 |
2 |
20 |
GPU3 |
NV6 |
NV6 |
NV6 |
X |
hsn3 |
216-287 |
3 |
28 |
HSN |
hsn0 |
hsn1 |
hsn2 |
hsn3 |
X |
Table Legend:
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
GPU NUMA ID
- this is the new feature of the GH200 where the CPU and GPU can see the memory domains.
- the domains are also visible via the numactl command.
numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287
cpubind: 0 1 2 3
nodebind: 0 1 2 3
membind: 0 1 2 3 4 12 20 28
Available Memory
Note that the amount of RAM available to jobs via the Slurm --mem option is 10 to 15 percent less than the total amount
installed because of memory reserved for the operating system.
Login Nodes
Login nodes provide interactive support for code compilation, job submission, and interactive salloc/srun. They do not contain GPUs. See DeltaAI Login Methods for more information.
Specialized Nodes
Delta supports data transfer nodes (serving the “NCSA Delta” Globus collection) and nodes in support of other services.
Network
DeltaAI is connected to the NPCF core router and exit infrastructure via two 100Gbps connections, NCSA’s 400Gbps+ of WAN connectivity carry traffic to/from users on an optimal peering.
DeltaAI resources are inter-connected with HPE/Cray’s 200Gbps Slingshot 11 interconnect.
Storage (File Systems)
Warning
Snapshots are only available for data in your /u directory, these snapshots are retained for 30 days. You are responsible for backing up your files in /projects and /work. For these areas there is no mechanism to retrieve a file if you have removed it, or to recover an older version of any file or data.
Note
For more information on the DeltaAI file systems, including paths and quotas, go to Data Management - File Systems.
Users of DeltaAI have access to three file systems at the time of system launch, a fourth relaxed-POSIX file system will be made available at a later date.
DeltaAI
The DeltaAI storage infrastructure provides users with their HOME, PROJECTS and WORK areas. These file systems are mounted across all DeltaAI nodes and are accessible on the DeltaAI DTN Endpoints. The HOME file system runs on a NCSA center-wide VAST system. The PROJECTS (see below) file system is provided by the NCSA Taiga center-wide, Lustre based file system. The WORK file systems run Lustre and have both a HDD (HardDisk Drive) and a NVME SSD (Non-Volatile Memory Express SolidState Drive) each with individual quotas.
Taiga
Taiga is NCSA’s global file system which provides users with their $PROJECT area. This file system is mounted across all Delta systems at /taiga (note that Taiga is used to provision the Delta /projects file system from /taiga/nsf/delta) and is accessible on both the Delta and Taiga DTN endpoints. For NCSA and Illinois researchers, Taiga is also mounted across NCSA’s Radiant compute environment. This storage subsystem has an aggregate performance of 110GB/s and 1PB of its capacity is allocated to users of the Delta system. /taiga is a Lustre file system running DDN’s EXAScaler 6 Lustre stack. See the Taiga documentation for more information.